
I first wrote about the Dance Card during the last year of the Herbble. As most people know, The Dance Card is the work of two college professors and self-proclaimed basketball junkies. They have attempted to reduce the Selection Committee process for awarding at-large bids to a mathematical formula (trying to hit the sweet point between simplicity and accuracy). Basically they use statistical analysis software (SAS) to determine which of many possible parameters correlate with the Selection Committee’s decisions.
At the time of my first entry on the Dance Card, the professors listed six factors that their formula was based on. At some point shortly after my first exposure to their work, they removed those factors from their website. I assumed that they were doing more analysis to improve their formula. Over the years they’ve talked about changing the formula, but were never specific about exactly what they were changing. I always hoped that they would post their key factors again.
This past Sunday I noticed that they’ve added a link to a paper on their pet project that was published in Oct 2016. Relax; I’m not going to discuss all of the various changes that the professors have gone through. I figure that the geeks amongst us will read the paper…and I won’t have to bore those that want the final answer without all the details about the long road traveled.
In any event, their latest equation [Equation (3) in the linked paper] uses the following factors:
- Overall RPI rank (using RPI formula in use prior to 2005)
- No. of conference losses below 0.500 record
- Wins vs. teams ranked 1–25 in RPI
- Wins vs. teams ranked 26–50 in RPI
- No. of road wins
- No. of wins above 0.500 record against teams ranked 26–50 in RPI
- No. of wins above 0.500 record against teams ranked 51–100 in RPI
Here was their summation of their latest equation:
Equation (3)’s attractiveness for potential use is also enhanced by its strong face-validity. For example, and as one would expect, the weight placed on wins against top 25 opponents (2.7509) is higher than the weight placed on wins against teams ranked 26–50 (1.2572). Similarly, the weight assigned to wins above 0.500 against teams ranked 26–50 is higher than the implied weight for wins above 0.500 against teams ranked 51–100 (1.2021 vs. 0.8364, respectively). It is also likely satisfying to those invested in the sport to find that wins against top 25 teams and wins on the road are apparently rewarded, whereby losses in such settings are not penalized. The same could be said of wins against teams ranked 26–50 getting consideration even if a team has a losing record against that same group. It is also likely unsurprising and welcomed that losses are also considered when examining performance against teams ranked 26–50 or 51–100, but a winning record is rewarded while a losing record is not penalized. Although the committee’s apparent penalizing of teams with losing conference records is evidence of behavior that is inconsistent with proclamations that the committee does not consider league membership or league standings (ASAPsports.com, 2015), this violation of stated procedures is one that many in the sport would likely find palatable.
Many of these factors are included in our various qualitative discussions on the Bubble and several are a little more esoteric. My bubble discussions are targeted more to tracking the ACC teams through the season with a final entry before the ACCT. I have never attempted to do the entire bracket like Lunardi or Palm so I’ve never attempted to come up with a technique to pick through the mid-majors. The strengths and weakness of my approach are pretty obvious since I do OK with the ACC; but not so good with the mid-majors. It would be interesting to talk to the professors and see if some factors are more important when looking at mid-majors versus the power conferences.
One part that I found particularly interesting was the section where they discussed some teams that their latest formula still missed….meaning teams that received a bid that was not predicted by their formula. Here’s an example:
Equation (3) correctly predicted 35 of the 36 at-large bids for 2014, missing only on North Carolina State (it predicted California to receive that bid instead). Only one of the 120 methods compiled by BracketMatrix.com in 2014 did better. Nearly all (117 of 120) of those other methods missed on North Carolina State as well, suggesting that the choice of North Carolina State was likely a matter of the committee simply deviating from its historical norms, and not a result of error in the modeling of those norms.
For those that don’t remember, that was the year that State (with ACC POY TJ Warren) was literally the last team in the field. Several other teams over the years were discussed in the paper including many that we discussed during that particular year. Of course, I called them “mistakes” (at least those selected not named NC State), but the professors chose the more PC phrase “deviating from its [NCAAT Selection Committee] historical norms“.
ADDITIONAL FACTORS ON NCAAT SELECTION
OOC SCHEDULING
Over the years, I’ve documented a number of different cases where it appears that the NCAAT has penalized teams for their cupcake OOC schedules. I remember those things about the Bubble that I’ve research and documented, but don’t remember actually researching the effect of cupcake OOC schedules on at-large bids. So I’m pretty certain that I originally got this tidbit from Jerry Palm when he was running his own blog/business at collegerpi.com (currently doing bracketology at cbssports.com). Here’s something of his I quoted after Seth Greenburg once again scheduled VT into the NIT:
Again this year, a team learned the hard way that you can’t take the first two months off and get a free pass into the tournament. This year, that team was Virginia Tech.
I really enjoyed Jerry’s old blog much more than what he puts up at cbssports.com. He has toned down his geek factor a lot, probably to reach a more uninformed public rather than a group interested enough in the dirty details to pay for his blog. In any event, I’m positive that I came up with the following formula on how to take a bubble team to the NIT:
Weak OOC Schedule +
Marginal Conference Performance +
Poor Conference Tournament Performance=
NIT
I say all of that to say that if some teams are going to schedule themselves into the NIT, that will leave a spot for another team to rise above the Dance Card burst point. A lot of people that didn’t understand the importance of OOC scheduling bitched about SMU getting left out in 2014 and State getting in. But this didn’t affect the Dance Card that year because they didn’t have SMU in the field anyway (but a couple of spots above State). The fact that SMU got left out didn’t surprise me. But State getting in that year was certainly a pleasant surprise.
“ADVANCED” METRICS
Fans of Pomeroy or Sagarin should enjoy this:
Pursuant to the findings of Paul and Wilson (2012) regarding the committee’s apparently greater reliance on rankings that consider margin of victory than on the RPI, equation (3) was iteratively re-fit while using the ranking of each of 25 different mathematical systems in place of RPIRANK. The list of ranking methods employed is shown in Table 4.12 The 25 systems employed were all those with pre-tournament rankings compiled at Massey (2013) for every year from 2009 through 2013. Some of these— e.g., the aforementioned LRMC model, the Sagarin ranking, and the ranking of Ken Pomeroy— have been shown to be superior predictors of tournament performance (Kvam & Sokol, 2006; Brown & Sokol, 2010), are well-known and respected in basketball circles, and are reportedly provided to the committee during its deliberations(NCAA, 2014b).
I agree that using point spreads improves one’s ranking of the teams in question. But ever since the disaster of using point spread in the BCS championship calculation led to teams intentionally running up the score on lesser teams, I’ve been against using point spreads in determining at-large NCAAT bids. While these so-called advanced systems may be provided to the Selection Committee, the Dance Card formula uses the old RPI formula because it showed a better correlation than any of these other ranking systems. So while these advanced systems may be provided and may be used on occasion, their use is not frequent or wide-spread enough to show up when compared to the old RPI calculation method (pre-2005).
But it looks like Pomeroy’s rankings may have led the selection committee into making a mistake last year. Specifically, I thought that the Wichita State selection was horrible. Here’s what foxsports.com had to say about several selection committee decisions and Pomeroy:
I’ve noticed for a couple years now that the committee is paying closer attention to advanced metrics like KenPom.com, particularly in evaluating bubble teams. Committee chairman Joe Castiglione cited them as to why Wichita State, 12th on KenPom, got an at-large berth despite an underwhelming resume. Vanderbilt (27th) also had that as its main calling card, while NIT-bound St. Bonaventure likely got dinged for its No. 79 rating.
Beating a bunch of nobodies to death shouldn’t outweigh actual wins against good teams. I guess that I’m concerned that the selection committee may be using “numbers” without understanding exactly what they mean. But since the stat wizards couldn’t correlate Pomery’s numbers with the at-large bids, maybe the Selection Committee only uses these advanced metrics when they’re trying to sort through a bunch of mid-majors. If so, then I don’t really care because I don’t generally care about the mid-majors. But just on principle, I don’t like using some different ranking system over the normal method of looking at quality wins. In any event, I guess that I will have to include Pomeroy’s rankings when we discuss bubble teams in my normal bubble entry after Selection Sunday.
For those addicted to brackets, note the statement that Sagarin and Pomeroy “have been shown to be superior predictors of tournament performance.” That’s just something to keep in mind.
CONFERENCE RECORD
I’m glad to see that the Dance Card found statistical support for my conclusion that a losing conference record was bad. It’s not that I’m bashful about defending my conclusions; it’s just nice to have more backup the next time an argument breaks out. We’ll have to see how Clemson and several other ACC teams perform down the stretch, but conference record could easily be a hot topic this year.
TOO CLOSE TO CALL
When you get down to the last few spots, there is frequently very little to separate one team from another. For example, look at teams a little on either side of the 2016 Bubble Bursting Point:

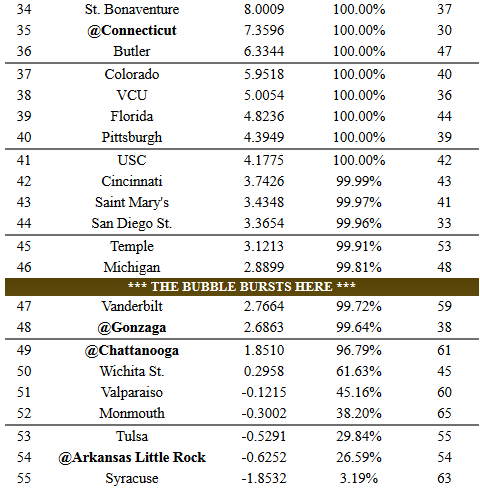
From the tone of the paper, I get the impression that the professors don’t get too upset when a team that they calculated just below the bubble gets picked over one that was just above. Differences that small are just too difficult to call and could well come down to personal preferences/prejudices of the Selection Committee members that year.
But sometimes the selections are a real surprise. The start/stop points of last year’s bubble shown above were intentional. Specifically, the Bonnies were left out and Syracuse was included in the NCAAT. The professors didn’t discuss these two so I don’t know exactly what they think about these two misses. I have to wonder if they are working on a new correlation or did they just chalk it up to the “Selection Committee ignoring historical norms”.
CONCLUDING THOUGHTS
I may be reading more into the following snippet than the authors intended:
Equation (3) appears to be a strong model of the at-large bid selection process. Its strength is a signal that the committee’s decisions are very consistent year-to-year despite the partial changeover in committee membership each year. In addition to its strong fit, its simplicity and easy replicability make it even more attractive as a predictive tool and as a potential decision aid to the selection committee.
I have to wonder if the professors are hoping or angling for their calculations to be used by the selection committee before the Sunday evening TV broadcast. Whether they are or not, I think that it would be an outstanding idea for the selection committee’s bracket to be “error-checked” before it is published. I was thinking that a 2-3 member team of past committee members should do a completely independent bracket and then this sub-committee could explain its reasons for choosing different teams than the actual selection committee. The official committee should still have the last word, but it never hurts to be questioned off-the-air about tough or strange decisions.
Over the years, we’ve discussed teams that just should not have been included and the occasional team that appears to have been screwed. An official error-trapping technique could only improve the selection process. Even easier/quicker than a sub-committee, using The Dance Card would highlight a few teams (usually less than six) that are worth one more look before the selection committee chairman goes on the air at CBS. Personally, I would rather see the Selection Committee use the Dance Card than either Pomeroy or Sagarin.
